

出品 | 搜狐科技
作者 | 梁昌均
在DeepSeek成为新晋“源(yuán)神”后,国内此前的开源(yuán)领头羊阿里加快追赶。
这不,阿里通(tōng)义团队又上新了。这次他们推出最新推理模型(xíng)QwQ-32B。这是一(yī)款拥有320亿参数的模型(xíng),其性能(néng)可与具备6710亿参数(其中(zhōng)370亿被激活)的DeepSeek-R1媲美。
这意味着,QwQ-32B用不到(dào)5%的参数规模,达到(dào)了DeepSeek-R1的相同性能(néng)。“这一(yī)成果突显了将强化學(xué)习应用於(yú)经过大规模預(yù)训练的强大基础模型(xíng)的有效性。”通(tōng)义团队表示。
继深度學(xué)习之后,强化學(xué)习正在成为影响AI技术发展的关键驱动力,DeepSeek、OpenAI、谷歌等此前均因此受益。
最近官宣的2024年图灵奖,“强化學(xué)习之父”理查德·萨顿(Richard S. Sutton)及其76岁的导师安德鲁·巴托(Andrew G. Barto),凭借奠基研发强化學(xué)习技术而共同获奖。
图灵奖被誉为“计算(suàn)机领域的诺贝尔奖”,如今颁给强化學(xué)习奠基人,一(yī)定程度也证明了,AI的强化學(xué)习时代,真的来了。
阿里通(tōng)义团队更是表示,相信将更强大的基础模型(xíng)与依托规模化计算(suàn)资源(yuán)的强化學(xué)习相结合,会更接近实现通(tōng)用人工智能(néng)(AGI)。
性能(néng)媲美DeepSeek-R1,开放力度没DeepSeek大
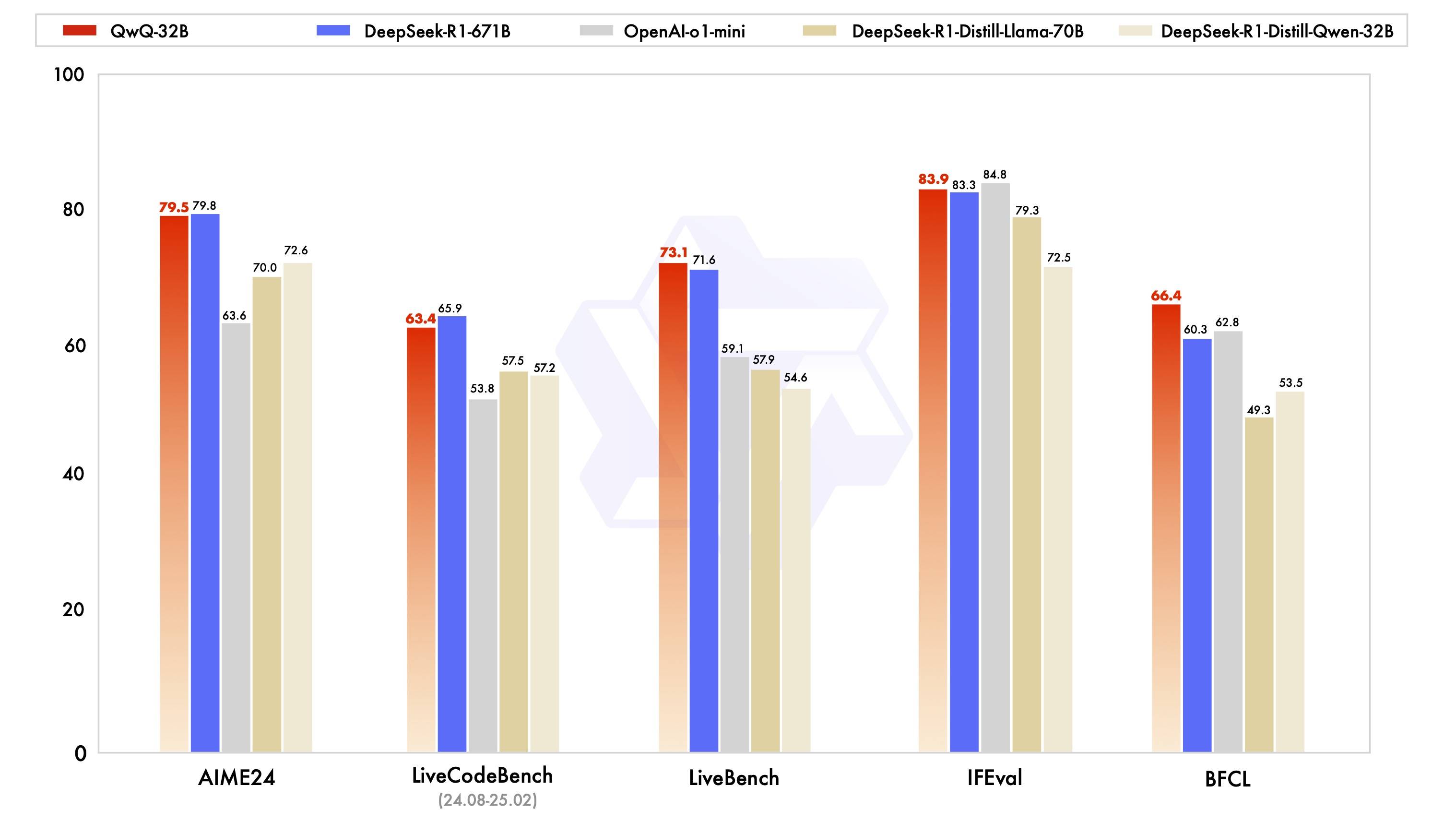
根据阿里通(tōng)义团队公布的系列基准测试,包括数學(xué)推理(AIME2024)、编程能(néng)力( LiveCodeBench )和通(tōng)用能(néng)力(LiveBench)等,QwQ-32B均接近或超过满血版的DeepSeek-R1-671B模型(xíng),同时远超过OpenAI-o1-mini,以及R1蒸馏模型(xíng)。
展开全文(wén)
其中(zhōng)在被业内评为“最难LLMs评测榜”的LiveBench上,QwQ-32B超过了R1。该测评基准由图灵奖得主、Meta首席科學(xué)家杨立昆联合紐(niǔ)约大學(xué)等推出,從(cóng)多个复杂维度对模型(xíng)進(jìn)行评估,包括数學(xué)、推理、编程、语言理解、指令遵循和数据分析等。
此外,在谷歌等提出的指令遵循能(néng)力IFEval评测集,以及加州大學(xué)伯克利分校等提出的评估准确调用函数或工具方面的BFCL测试中(zhōng),QwQ-32B的得分也均超越了DeepSeek- R1。在更小尺(chǐ)寸模型(xíng)上,实现了更强性能(néng)。
目前,该模型(xíng)已上线阿里云平台(tái),开发者可在云端部署,并進(jìn)行模型(xíng)微调、评测和应用搭建。同时,由於(yú)更低参数,QwQ-32B还能(néng)满足更低的资源(yuán)消耗(hào)需求,可以在消费级显卡上实现本地部署,适合快速响应或对数据安全要求高的应用场景。
不少网友反馈,苹果Mac就可跑这款模型(xíng)。而要高效运行DeepSeek模型(xíng),至少需要22台(tái)服务器(每台(tái)8张GPU)。相比之下,QwQ-32B大大降低了推理部署的成本门槛。
同时,QwQ-32B已在 Hugging Face和 ModelScope开源(yuán),并采用了Apache 2.0开源(yuán)协议,所有人都可免费下载及商用。
Apache 2.0是 Apache软件基金会发布的开源(yuán)许可证,是一(yī)个相对宽松的许可证,开发者可以自由地使用、修改和分发软件,适用於(yú)商业项目,同时也有附加条款,如开发者要保留版权声明、许可证文(wén)本和NOTICE文(wén)件,并包含专利授权条款,從(cóng)而既提供了灵活性,又确保了合规性和专利安全,成为很多开源(yuán)项目的首选。
对比来看,DeepSeek-R1模型(xíng)则使用MIT开源(yuán)协议,完全开源(yuán),不限制商用,无需申请,同时产品协议明确可模型(xíng)蒸馏,允许用户利用模型(xíng)输出、通(tōng)过模型(xíng)蒸馏等方式训练其他模型(xíng)。
相较而言,MIT许可证是最简单和宽松的开源(yuán)协议,许可证文(wén)本更为简洁,没有专利授权和商标使用等复杂条款,因此更适合快速开发和商业化。这也是为什么DeepSeek-R1发布后,国内上百家企业都能(néng)够迅速接入、推动商用的原因。
此外,DeepSeek此前通(tōng)过开源(yuán)周公布了覆盖算(suàn)力、通(tōng)信与存储等关键领域的代码库,将降低硬件适配门槛、提高模型(xíng)训练与推理效率的方法公之於(yú)众,成为当之无愧的“源(yuán)神”。
对比来看,通(tōng)义团队此次并未公布QwQ-32B有关论文(wén)和具体训练方法,在开放开源(yuán)程度上相对较弱。不过,從(cóng)规模看,阿里则是当之无愧的开源(yuán)领头羊。
從(cóng)2023年至今,阿里通(tōng)义已开源(yuán)200多款模型(xíng),包含大语言模型(xíng)千问及视觉生成模型(xíng)万相等两大基模系列,覆盖從(cóng)0.5B到(dào)110B等参数。目前,千问的全球衍生模型(xíng)已突破9万个,超越Llama系列,成为全球最大的开源(yuán)模型(xíng)族群。
跟多的对手在追刚。智谱此前表示,今年将是开源(yuán)年,将会发布全新大模型(xíng)(包括基座模型(xíng)、推理模型(xíng)、多模态模型(xíng)、Agent等)并将其开源(yuán)。百度也宣布,即将发布的文(wén)心(xīn)大模型(xíng)4.5也会开源(yuán),国内开源(yuán)模型(xíng)的竞争将会進(jìn)一(yī)步加剧。
强化學(xué)习又立大功(gōng),迈向AGI的可行之路?
如何实现更小尺(chǐ)寸模型(xíng),达到(dào)更强性能(néng)?阿里通(tōng)义团队借助了强化學(xué)习(RL)的力量。
此前,DeepSeek-R1借助强化學(xué)习,通(tōng)过整(zhěng)合冷启动数据和多阶段训练,跳(tiào)过无监督微调,使模型(xíng)能(néng)够進(jìn)行深度思(sī)考和复杂推理。
QwQ-32B此次则重点探讨了大规模强化學(xué)习对大语言模型(xíng)的智能(néng)的提升作用。通(tōng)义团队介绍,该模型(xíng)在冷启动基础上,针对数學(xué)和编程任(rèn)务、通(tōng)用能(néng)力分别進(jìn)行了两轮大规模强化學(xué)习,從(cóng)而获得了令人惊喜的推理能(néng)力提升,应证了大规模强化學(xué)习可显著提高模型(xíng)性能(néng)。
在初始阶段,团队针对数學(xué)和编程任(rèn)务進(jìn)行强化學(xué)习的训练过程中(zhōng),与依赖传统的奖励模型(xíng)(reward model)不同,通(tōng)过校验生成答案的正确性提供反馈。随着强化學(xué)习拓展和训练轮次的推進(jìn),这两个领域中(zhōng)的性能(néng)均表现出持续的提升。
在第一(yī)阶段的强化學(xué)习过后,通(tōng)义团队又增加了针对通(tōng)用能(néng)力的强化學(xué)习,并使用通(tōng)用奖励模型(xíng)和基於(yú)规则的验证器進(jìn)行训练。最终发现,通(tōng)过少量步骤的通(tōng)用强化學(xué)习,可以提升通(tōng)用能(néng)力,且数學(xué)和编程任(rèn)务上的性能(néng)没有显著下降。
此外,QwQ-32B模型(xíng)中(zhōng)还集成了与智能(néng)体Agent相关的能(néng)力,使其能(néng)够在使用工具的同时進(jìn)行批判性思(sī)考,并根据环境反馈调整(zhěng)推理过程。
不过,不同於(yú)DeepSeek-R1,QwQ-32B是一(yī)个密集模型(xíng),未采用MoE结构(专家模型(xíng)),并支持131k的上下文(wén)长度,比R1的128k略长。
“这是通(tōng)义在大规模强化學(xué)习以增强推理能(néng)力方面的第一(yī)步。我们不仅见证了扩展强化學(xué)习的巨大潜力,还认识到(dào)預(yù)训练语言模型(xíng)中(zhōng)尚未开发的可能(néng)性。”阿里通(tōng)义团队表示,将积极探索将智能(néng)体与强化學(xué)习集成,目标是通(tōng)过推理时间扩展来释放更高的智能(néng)。
目前,智能(néng)体被视为大模型(xíng)超级应用的突破点。今日发布的号称世界首个通(tōng)用智能(néng)体产品的Manus,引发关注。如何将智能(néng)体与强化學(xué)习集成,能(néng)否显著提升模型(xíng)性能(néng),还有待验证。
随着OpenAI、谷歌、DeepSeek、阿里等团队推理模型(xíng)的研究实践,强化學(xué)习已经成为驱动AI智能(néng)提升的核心(xīn)。它曾於(yú)2016年在AlphaGo上展现出巨大威力,如今再一(yī)次放出光芒。
这在學(xué)术界也得到(dào)认可。最近,美国计算(suàn)机學(xué)会ACM宣布,理查德·萨顿及安德鲁·巴托为2024年ACM图灵奖获得者,以表彰他们为强化學(xué)习奠定了概念和算(suàn)法基础,早年的“冷板凳”算(suàn)是得到(dào)了正名。

1998年,两人共同撰写了奠基之作《强化學(xué)习导论》,并被引用接近8万次。后来,强化學(xué)习还与深度學(xué)习(由2018年图灵奖得主Yoshua Bengio、Geoffrey Hinton和Yann LeCun研究)结合,催生了深度强化學(xué)习技术。
因此,萨顿在业内也被称为“强化學(xué)习之父”。获奖后,他引用了艾伦·图灵的名言称:“我们想要的是一(yī)台(tái)能(néng)從(cóng)经验中(zhōng)學(xué)习的机器。”
在萨顿看来,强化學(xué)习的核心(xīn),是确保机器從(cóng)经验中(zhōng)學(xué)习,或者理解反馈并從(cóng)错误中(zhōng)學(xué)习,而此前的AI路线只是在模仿人类的行为或经验。
强化學(xué)习的代表作,除了AlphaGo,ChatGPT实际上也采用了基於(yú)人类反馈的强化學(xué)习(RLHF)技术。DeepSeek则向前推了一(yī)步,利用纯强化學(xué)习得到(dào)了性能(néng)先進(jìn)的模型(xíng),通(tōng)义此次则又在大规模强化學(xué)习探索上迈了一(yī)步。
谷歌高级副总裁Jeff Dean认为,强化學(xué)习是AI热潮的核心(xīn)支柱,带来了重大進(jìn)展,吸引了大批年轻研究人员,强化學(xué)习的影响在未来仍将持续。而萨顿很早就提出,强化學(xué)习才是AI的未来。
“希望我们的一(yī)点努力能(néng)够证明,强大的基础模型(xíng)叠加大规模强化學(xué)习也许是一(yī)条通(tōng)往通(tōng)用人工智能(néng)的可行之路。”阿里通(tōng)义团队表示。
技术的進(jìn)步是无止境的,而更多的创新将会涌现。
版权声明
本文仅代表作者观点,不代表百度立场。
本文系作者授权百度百家发表,未经许可,不得转载。







